当我们做美颜、虚拟背景、虚拟人偶等功能时,一般都是需要对 iOS 相机帧进行前置处理。如果做过 iOS 开发的话,很快可以写出来下面的处理过程代码。
- (void)captureOutput:(AVCaptureOutput *)captureOutput
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection *)connection {
CVPixelBufferRef pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVPixelBufferRef resultPixelBuffe = [self handler:pixelBuffer];
[self renderPixbuffer:resultPixelBuffe];
}
上面的代码看起来没啥问题,不出意外应该也可以顺利的运行起来。下面我们就逐步来看会遇到什么问题。
视频卡顿问题
当你写的代码运行的时间比较久时,手机发烫性能下降时会发现延时感非常强烈,看到的自己的画面很可能是5秒之前的画面。主要的原因就是性能下降时,手机的硬件处理速度下降,相机的视频帧的采集速度和处理速度不能匹配,造成了视频帧堆积引起的问题。
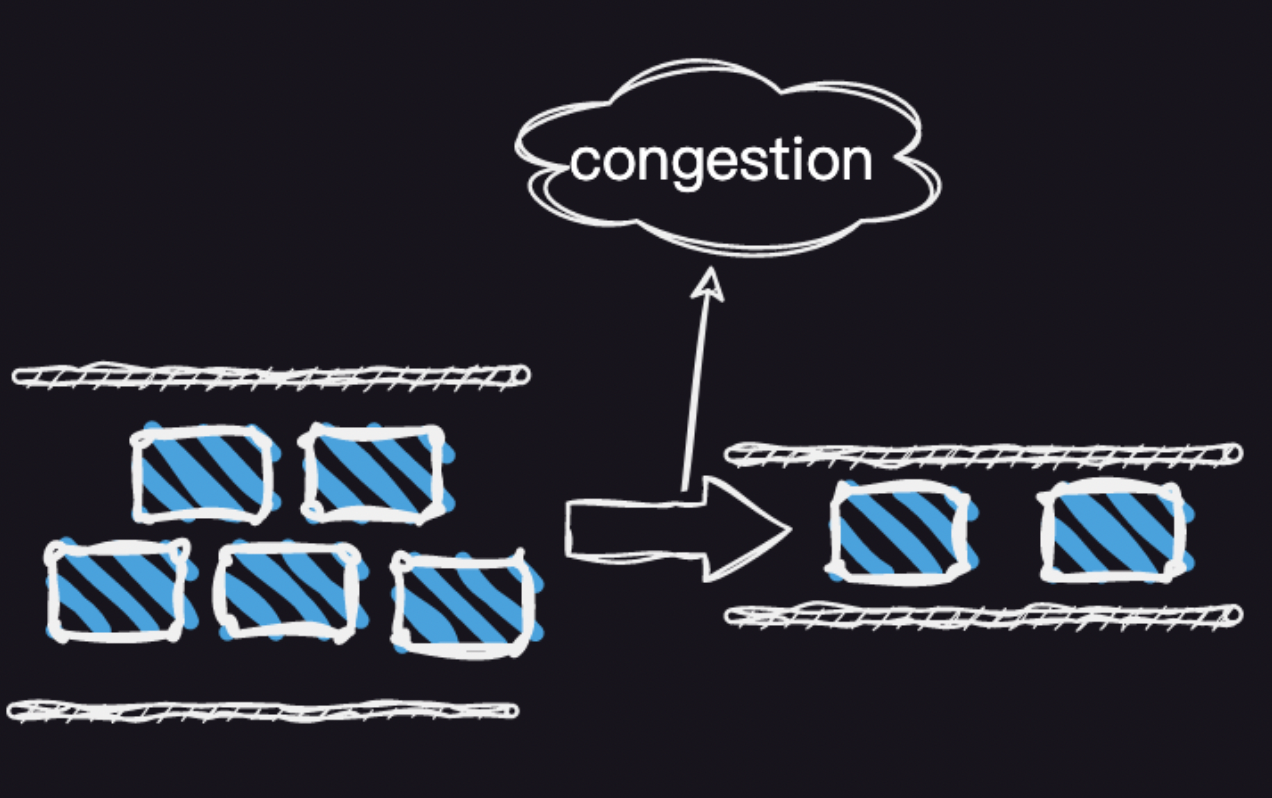
上图很形象的展示了这个过程,系统相机采集帧的线程队列优先级往往比较高,当遇到我们的帧处理线程时。相当于高速公路上的汽车突然来到了省道上,如果系统性能比较好时,高速公路不繁忙那么自然不会拥堵,当系统性能下降时很容易遇到上图示例展示的拥堵,这时候用户看到的视频帧自然就会延时的很厉害。
线程的优化
既然遇到了拥堵问题,那我们怎么优化呢?第一个想到的是,不要卡主系统相机采集线程的回调,通过设置另一个线程队列来处理我们的视频帧,自然会写出下面的代码。
_frameQueue = dispatch_queue_create("org.dingtalk.cameravideocapturer.video", DISPATCH_QUEUE_SERIAL);
// 提升视频帧处理线程队列的优先级,
dispatch_set_target_queue(_frameQueue, dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_HIGH, 0));
- (void)captureOutput:(AVCaptureOutput *)captureOutput
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection *)connection {
CVPixelBufferRef pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVBufferRetain(pixelBuffer);
dispatch_async(self.frameQueue, ^{
CVPixelBufferRef resultPixelBuffe = [self handler:pixelBuffer];
[self renderPixbuffer:resultPixelBuffe];
CVBufferRelease(pixelBuffer);
}
}
这种想法是没有问题的,但是现实很残酷,虽然你切换了处理线程,并且也提升了线程的优先级,相当于吞吐量增加了。但是遇到性能下降时,尤其像美颜、虚拟背景处理视频帧花费的时间会比较长。会造成的问题是,有大量的视频帧囤积到内存中,然后等待你的 frameQueue 队列去处理。如果观察内存的变化情况就如下图:
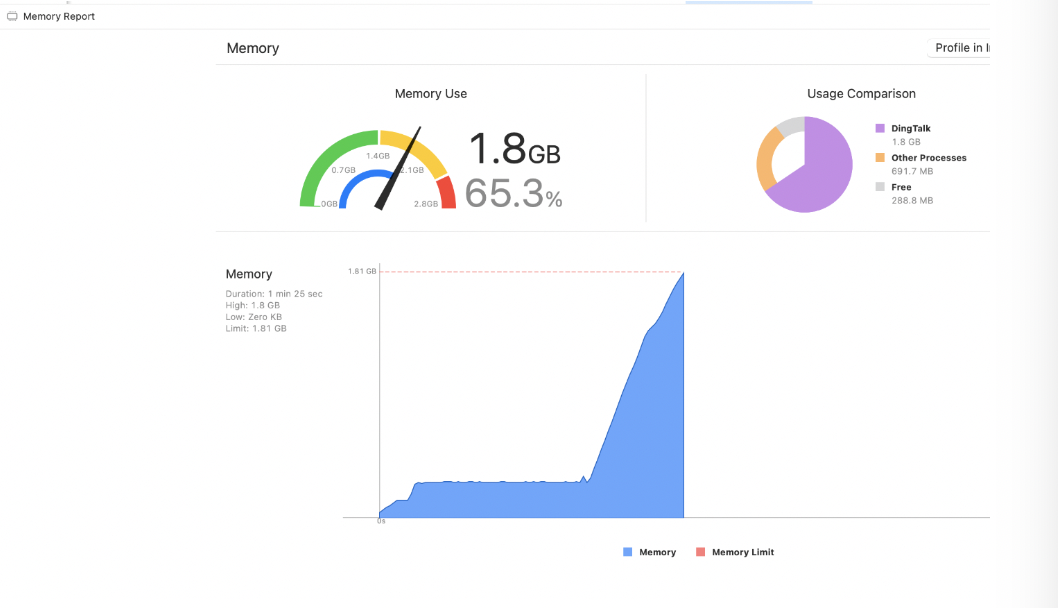
并且在手机发烫,CPU 性能下降时,每帧视频处理时长会越来越长,导致内存不断增加形成恶性循环,最终的结果就是 OOM 程序崩溃。
为何内存会囤积到内存中,等待 frameQueue 线程队列执行呢?这就涉及到我们使用的一个操作 dispatch_async。下面展示下 dispatch_async 的源码实现。
void
dispatch_async(dispatch_queue_t queue, dispatch_block_t block)
{
struct dispatch_continuation_s contin;
dispatch_continuation_init(&contin, block, 0, queue, 0, 0);
_dispatch_async_f(queue, &contin, NULL, NULL, NULL, DISPATCH_INVOKE_ASYNC_BIT, 0);
}
DISPATCH_NOINLINE
static void
_dispatch_async_f(dispatch_queue_t dq, dispatch_continuation_t dc,
void *ctxt, dispatch_function_t func, void *dc_func,
uint64_t dc_data, uint64_t dc_flags)
{
// ...
dq->dq_items_tail->do_next = dc;
dq->dq_items_tail = dc;
if (slowpath(dq->dq_width == 1)) {
// 如果是串行队列,直接执行任务或唤醒runloop
_dispatch_queue_push_list(dq);
}
// 如果是并发队列,直接将任务添加到队列尾部
}
我们总结下,dispatch_async 主要做了下面两个事情。
- 如果 dq 是串行队列,它会直接执行 dc 中的任务或唤醒 runloop 来执行任务。
- 如果 dq 是并发队列,它只会简单地将 dc 添加到队尾,等待后续被线程查找并执行。
可以看出 dispatch_async 的主要工作是将任务加入队列,并根据队列类型来决定是否直接执行任务。所以当我们定义一个串行队列时。本质上就是不停的往队列中放置数据,如果放置的队列中有大数据,而我们又没做相应的丢弃操作,就很容易引起内存堆积问题。
丢帧优化
为了防止上述的 OOM 的情况,最容易想到的就是对堆积的队列做丢帧的处理。可以通过设置丢帧的间隔,比如设置0.1秒间隔,如果处理不完就丢弃掉后面来的视频帧,可以写如下的代码。
_processSemaphore = dispatch_semaphore_create(1);
- (void)captureOutput:(AVCaptureOutput *)captureOutput
didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer
fromConnection:(AVCaptureConnection *)connection {
CVPixelBufferRef pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
CVBufferRetain(pixelBuffer);
patch_async(self.frameQueue, ^{
if (dispatch_semaphore_wait(self.processSemaphore, dispatch_time(DISPATCH_TIME_NOW, (int64_t)(0.1 * NSEC_PER_SEC))) != 0){
CVBufferRelease(pixelBuffer);
return;
}
CVPixelBufferRef resultPixelBuffe = [self handler:pixelBuffer];
[self renderPixbuffer:resultPixelBuffe];
CVBufferRelease(pixelBuffer);
dispatch_semaphore_signal(self.processSemaphore);
}
}
上述的代码,可以用下图形象的展示:
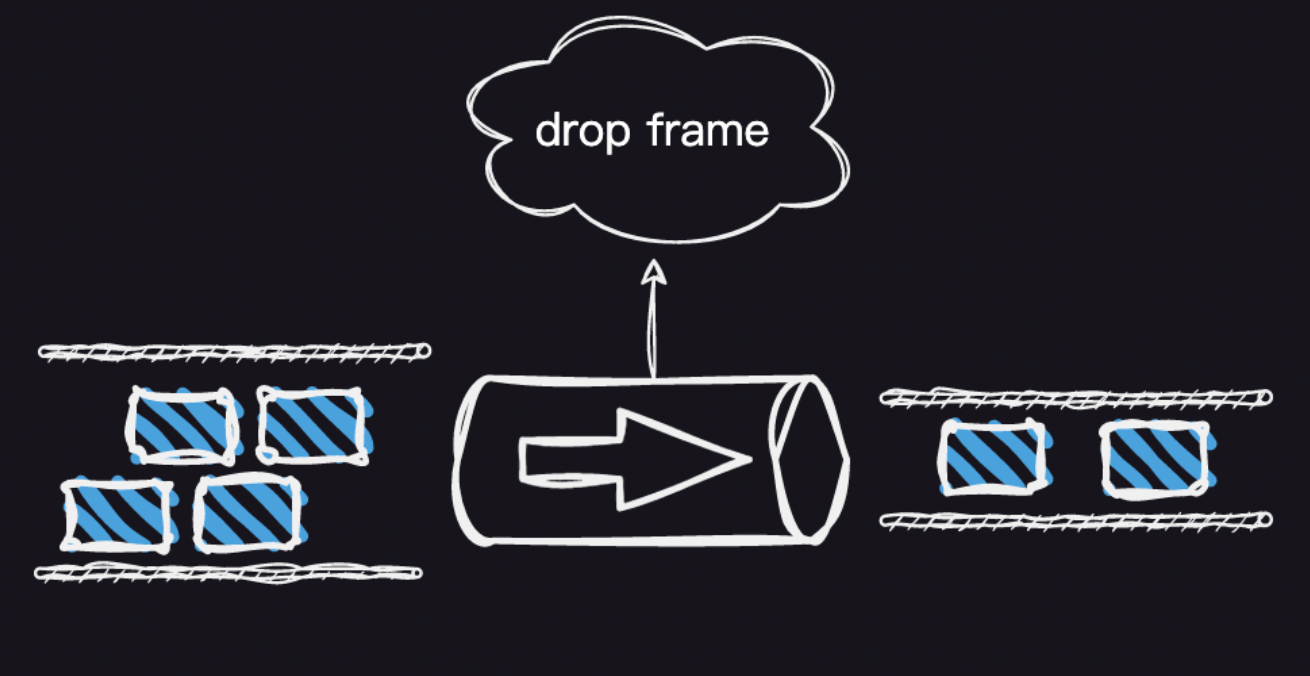
这里相当于给高速公路设置了一个分流站,不合格的车辆直接当场扔掉(这样有点残暴,当然这里只是假设)。似乎用这种方式可以解决内存堆积问题。我们的程序用这种方式继续运行,会带来另一个问题。虽然内存不会持续增加了,但是内存会出现过山车的情况忽上忽下。如果用 instument 观察就如下面的现象。
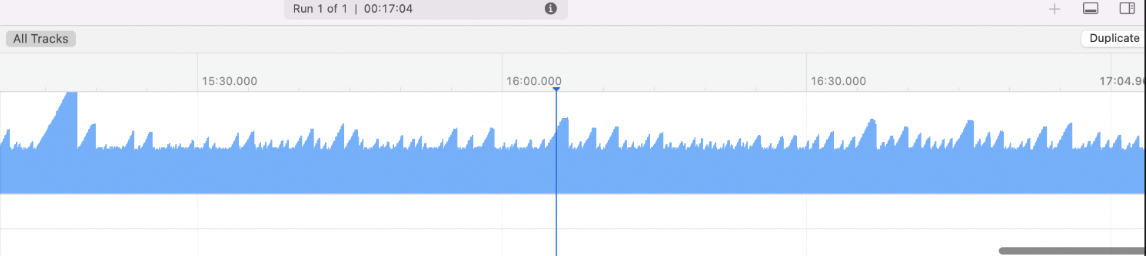
这种情况虽然不至于让程序很快崩溃,但是也是在危险的边缘不停的试探,一旦一次触发到底线还是会崩溃的。那我们如何解决呢。
缓存队列
从上面的代码可以看到,之所以形成了过山车内存的问题,并不是采集问题引起的。因为采集线程已经做了丢帧的操作。我们把问题用下图描述。
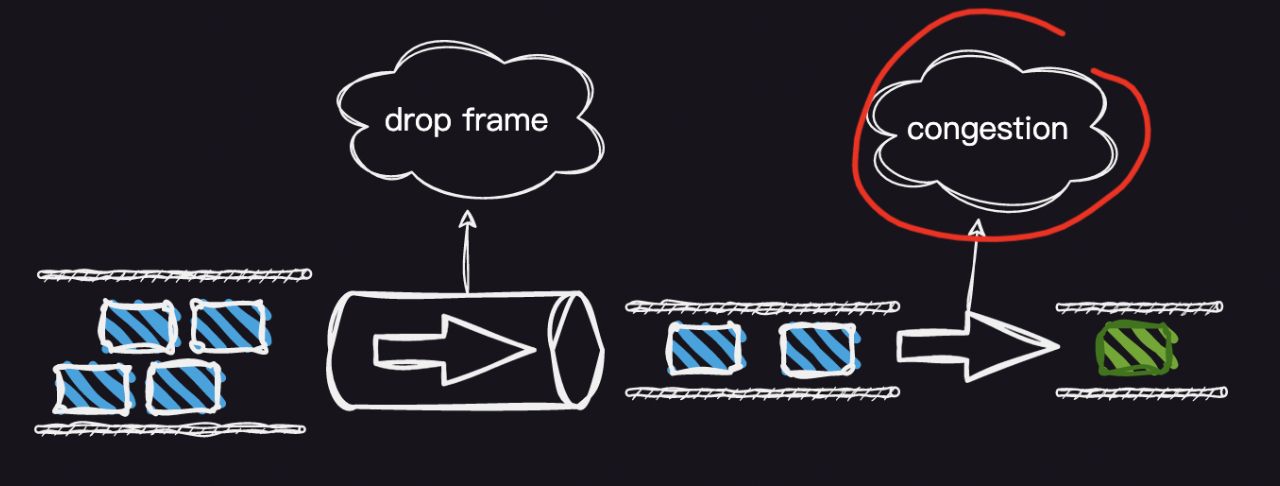
可以看出主要原因是处理线程完成后,在渲染时由于采集和渲染在同一个 framequeue 线程中,会造成我们最开始描述的视频帧拥堵问题。那我们如何解决这个问题,和上面描述的优化逻辑一样,首先要把采集的线程和渲染线程分离开,然后再做丢帧的操作。这里我们可以通过增加一个缓存队列来做,实现代码如下:
CVBufferRetain(pixelBuffer);
CVPixelBufferRef willDropPixelBuffer = NULL;
[self.pixelBuffersLock lock];
if (self.pixelBuffers.count >= kRTCMaxDropPixBufferFrame) {
willDropPixelBuffer = (__bridge CVPixelBufferRef)[self.pixelBuffers objectAtIndex:0];
[self.pixelBuffers removeObjectAtIndex:0];
}
[self.pixelBuffers addObject:(__bridge id)pixelBuffer];
[self.pixelBuffersLock unlock];
if (willDropPixelBuffer != NULL) {
CVBufferRelease(willDropPixelBuffer);
}
那为何采集的时候通过设置 0.1 秒的时间间隔来丢帧,而渲染要通过缓存队列来丢帧呢?其实本质上一样的,只是丢弃帧的逻辑不太一样而已,因为相机采集的帧回调的数据比较多,通过时间间隔丢帧可以更好的控制帧率,防止画面抖动太厉害。而渲染时就没必要这么精准的控制,通过丢弃过老的帧来防止内存抖动问题就可以了。然后我们优化后视频帧的整个处理过程就如下图所示:
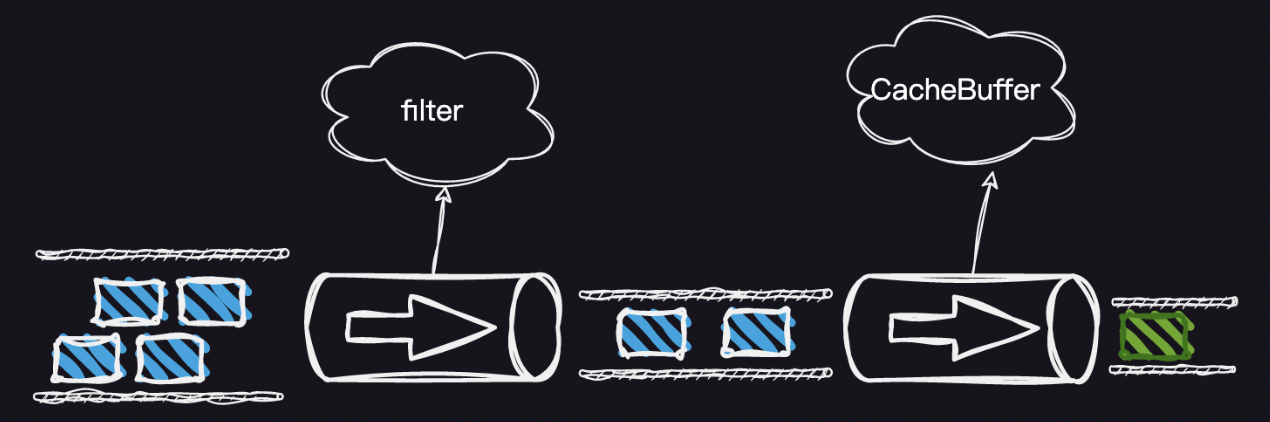
我们总结下,解决视频帧处理遇到的问题,主要通过下面两个手段来防止:
- 分离相机帧采集的线程队列和渲染的队列 (frameQueue、renderQueue),防止采集线程处理慢时造成渲染线程被卡住。
- 在两个线程队列切换时,增加数据丢帧逻辑防止内存 OOM。
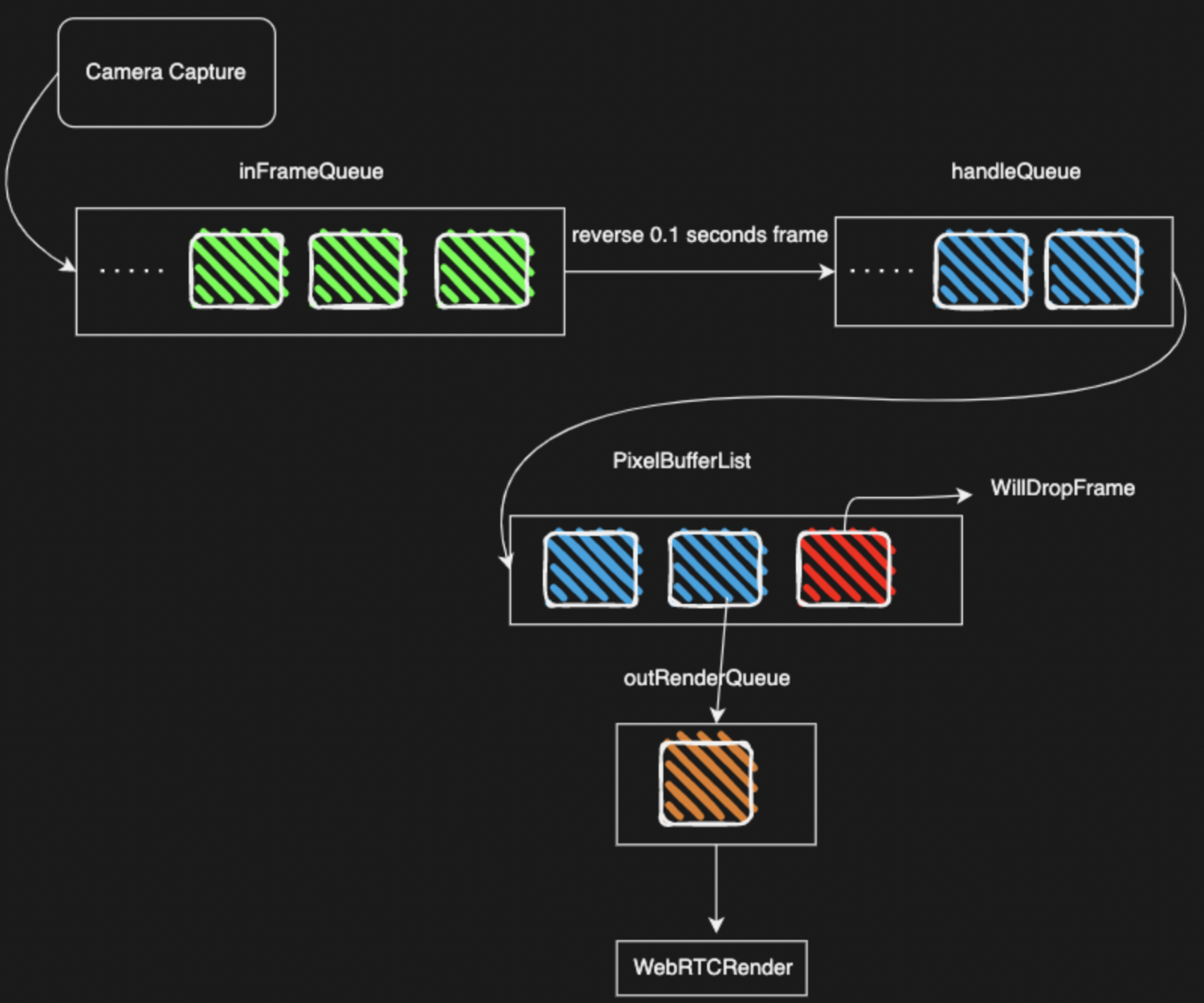
最终改造后的流程图如下:
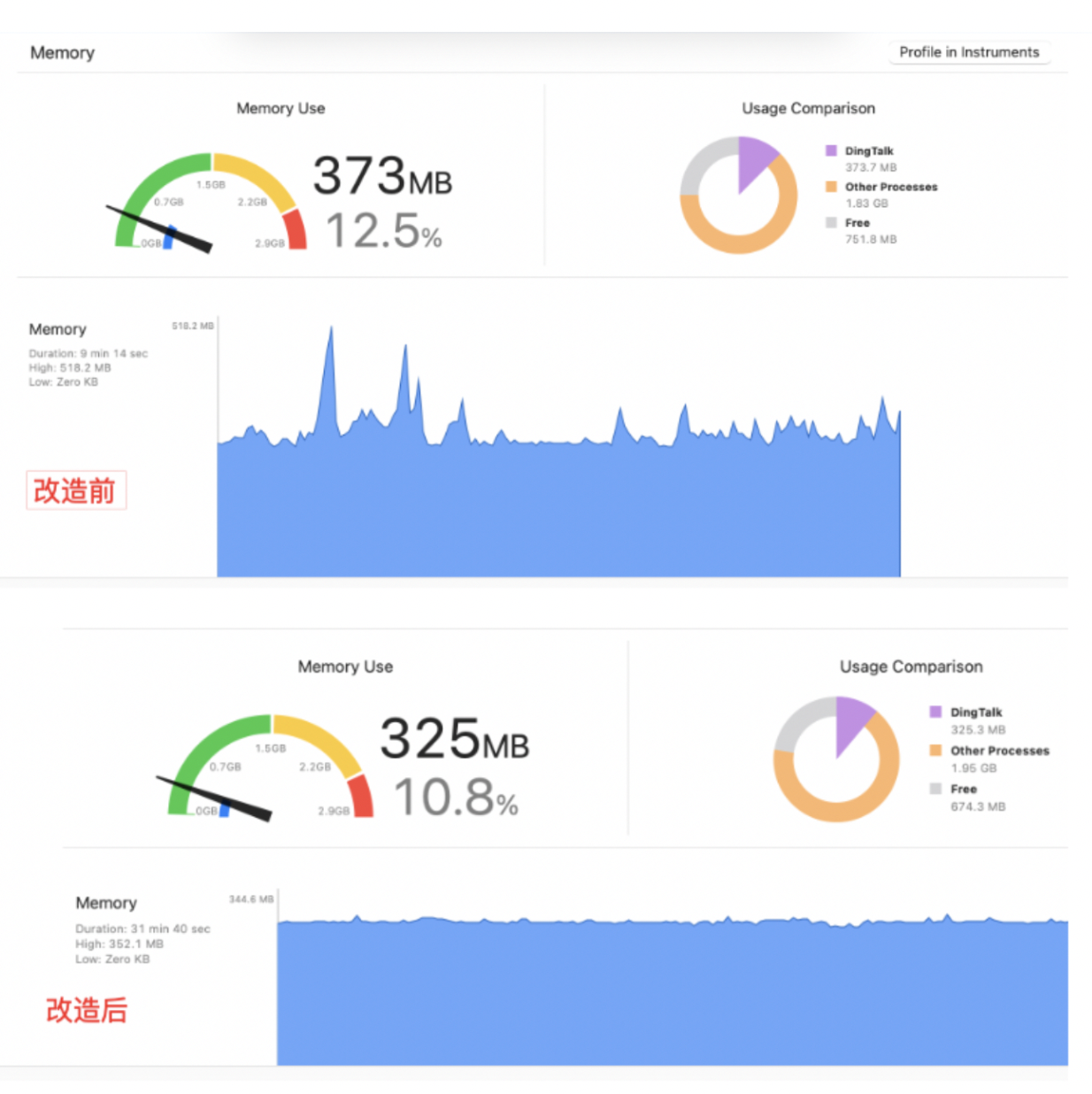
改造之前和改造之后,用 Instument 观察内存的抖动情况,可以明显的看到区别。
总结
上述虽然描述的是视频帧的处理优化过程。其实所有大的内存数据管道化处理时,都应该遵循下面的基本原则:
- 各个功能模块分别用不同的线程来处理,这样彼此互相独立不会相互影响数据的处理过程,避免拥塞卡顿问题。
- 在功能线程切换时传递的内存大数据,通过设置缓存 Buffer 避免引起内存问题,防止内存过多造成 OOM。
下面我们看下业界比较优秀的 WebRTC 音视频数据的处理过程,如下图所示:
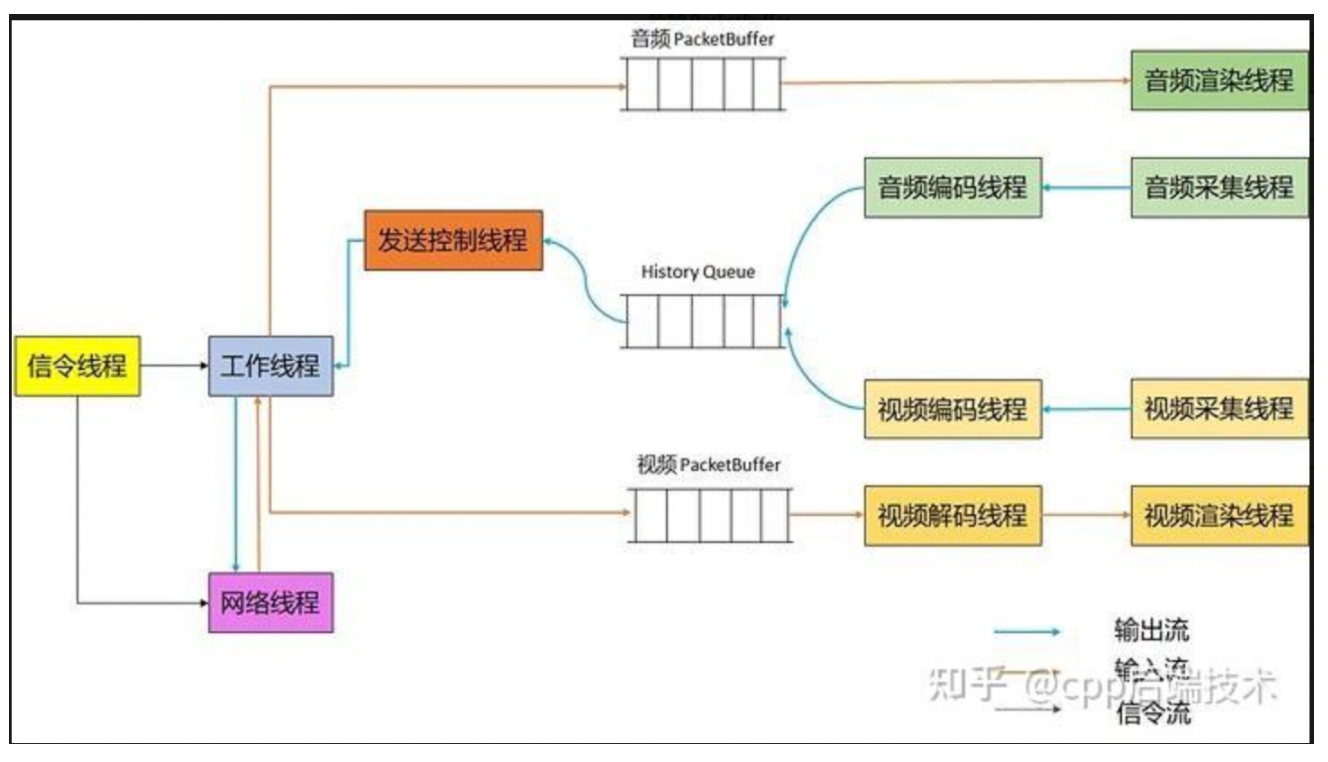
WebRTC 的视频采集、混合、编码、发送的过程,都是分别使用不同线程,并且都有相应的 Buffer 做缓存操作,非常符合上面我们视频帧优化的整个过程。所以我们在做这种大内存数据处理时尤其要铭记上面提到的两个原则。
